近年来,深度学习算法在医学图像分割领域取得了良好的效果。相比传统的机器学习和计算机视觉方法,深度神经网络在分割精度和速度等方面都具有一定的优势。然而,目前的深度学习算法仍然主要依靠训练数据来驱动,缺乏相关的医学领域知识(domain knowledge)的指导,需要大量的手工标记数据用于训练。由于医学图像数据量较大,人工标记耗时费力且包含主观误差,难以提供大量高质量的手工标记训练数据,从而限制了深度学习方法在医学图像分割领域的应用。半监督方法通过引入domain knowledge降低了算法对人工标记数据的需求量,很大程度上缓解了数据标注的难度,是解决数据标记问题的一种重要途径。今天为大家介绍两篇通过半监督方法来减少医学图像分割深度神经网络训练数据的前沿论文。这两篇文章从不同的角度利用了解剖学先验知识作为domain knowledge来减少人工标记的训练数据量:第一篇是帝国理工学院郭毅可教授课题组的Transfer Learning from Partial Annotations for Whole Brain Segmentation [1],发表于MICCAI 2018论文集,第一作者是Chengliang Dai。这篇文章提出了新型的多任务学习框架来解决全脑分割问题。该框架利用大量自动生成的具有部分标签的图像和少量手工标注的具有完整标签的图像进行训练,达到了与目前全脑分割最先进方法相当的性能。在2019年的西安ISICDM会议上,郭教授的大会报告也提及了这个工作。
第二篇是Removing Segmentation Inconsistencies with Semi-Supervised Non-Adjacency Constraint [2],发表于2019年的Medical Image Analysis杂志,作者是法国里昂大学的Pierre-Antoine Ganaye等人。这篇文章为深度网络加入了脑区之间相邻关系作为解剖学先验知识约束,来改进分割结果中像素标签孤立破碎的问题。因为这种区域相邻关系的约束适用于未标记的数据,所以该方法除了可以用于全监督网络也可用于半监督网络。下面来详细介绍这两篇工作。
1. Transfer Learning from Partial Annotations for Whole Brain Segmentation为了减少人工标记的训练数据量,第一篇文章的核心思路是采用transfer learning的办法。作者采用两步走的策略(two stages training):第一步是先用传统的脑图谱配准算法自动生成大量的含有标签的训练数据集,并以这些自动生成的标签数据训练得到first stage network;第二步,以first stage network为基础做transfer learning,用为数不多的人工标记数据与先前的大量自动标记数据一起训练更加精准的second stage network。需要注意的是,第一步的所采用的自动生成的训练数据中脑区标签的数量远小于第二步中的人工标记脑区标签数量,而第二步采用两种标记数据做混合训练时采用的是多任务学习的方式(每种数据作为一个任务)。下面对这篇论文的算法细节做一下介绍。
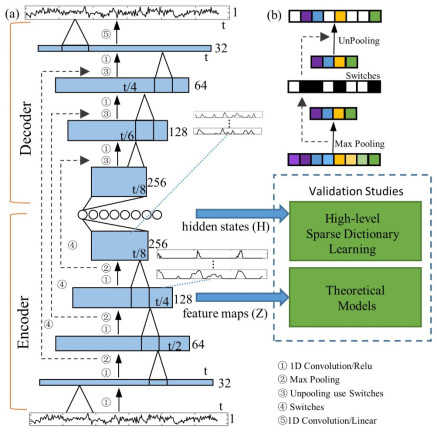
这篇在解决脑部MRI图像全脑分割问题时提出了一种两阶段训练的方式,包括预训练阶段和联合训练阶段。在第一阶段中使用4000例自动生成的只包含15个脑区标签的MRI图像训练一个常见的3D U-Net网络(Encoder+Decoder的经典结构),使用分类交叉熵作为损失函数,如图1中Stage 1红色方框中所示。由于第一阶段的监督仅仅是自动生成的图像,所以得到的网络可能会存在错分的情况且只包含了为数不多的15个标签。在得到第一阶段的网络后进行第二阶段的多任务学习,此时Encoder仍然使用第一阶段网络中的Encoder,但是Decoder有两个,每个Decoder对应一个学习任务。第一个Decoder仍然采用Stage1训练得到的针对15个脑区标签的Decoder,其所对应的训练数据仍是之前自动生成的4000个15脑区标签数据;第二个Decoder则针对含有大量脑区标签(几十个甚至上百个)的手工标记训练数据,但是这些手工标记的训练数据只有二、三十例。在第二阶段的训练中,Encoder和两个Decoder都使用预先加载第一阶段训练好的权重,而所使用的损失函数是两个Decoder损失函数结合起来的加权损失函数。这种多任务的设计可以让网络学习到更多部分标签和全标签训练数据中共有的特征。而且在这一阶段中,由于手动分割的标签要比第一阶段中自动生成的标签的准确度更高,所以网络可以修正在第一阶段训练中的一些不足,从而得到更好的部分分割结果。

图1. 第一阶段和第二阶段训练中使用的网络架构文章通过Dice来衡量所提出的多任务网络(MO-Net)的性能,并训练了两个U-Net进行比较,一个是在MICCAI 2012 Multi-atlas Labelling Challenge (MALC)数据集上从头训练的(U-Net (FS)),一个是在Hammers Adult Atlases (HAA)数据集上进行微调的(U-Net (FT))。在MALC数据集上还与基于fine-tuning 8和27的3D U-Nets SLANT8和SLANT27进行了比较,结果如下:

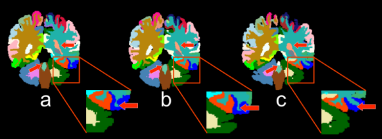
可以看到MO-Net明显优于U-Net (FS),与U-Net (FT)、SLANT8和SLANT27相比也略有提升。图2是三种方法在HAA数据集上对大脑左半球8个结构分割结果Dice的箱线图。图3定性地展示了分割结果,MO-Net在某些结构中具有更好的分割精度。

图2. 三种方法在HAA数据集上对大脑左半球8个结构分割结果Dice的箱线图

图3. (a) 金标准. (b) MO-Net. (c) U-Net (FT).
2. Removing Segmentation Inconsistencies with Semi-Supervised Non-Adjacency Constraint第二篇文章在网络训练时引入了一种基于区域相邻关系的损失函数NonAdjLoss,来惩罚在解剖学相邻关系上不正确的分割标签输出。这篇文章的主打创新点是采用脑区之间相邻关系作为图像分割的解剖学先验知识,从而减少分割结果中鼓励破碎的脑区标签。作者并没有主要突出这个创新点对于减少人工标记的作用,然而这个“副作用”的潜力是显而易见的。
具体的做法是通过一个相邻关系矩阵Α表示不同脑区的相邻关系矩阵,其中每一行或每一列代表一个脑区,矩阵元素Αij表示标签分别为i和j的两个脑区相邻的像素总数。由于不同个体间可能存在差异,对Α进行二值化得到Ã,则当脑区i和j在训练数据中相邻时,Ãij=1,否则为0,如图4所示。相邻关系矩阵从注释标签图中得到,并作为训练时的金标准,认为每一个样本都应该具有相同的临接规则。此时定义一个关于网络参数W的约束函数G(w),当所有标签的连接关系都满足相邻关系矩阵Α的约束时,G(w)值为0,并随着不满足Α约束的像素数增大而增大。

其中Ι表示灰度值图像,

为网络输出,

表示根据网络输出的概率图来衡量连接关系,

中错误的连接关系数量增大时,

随着增大。在训练中,如果网络输出的结果不符合邻接约束条件,则使用NonAdjLoss对网络进行惩罚。在实践中需要用标准损失函数预训练网络,在激活NonAdjLoss之后,NonAdjLoss所占的权重也是随着迭代过程逐步增大的。初始时,λ=0.3,过高的λ(如0.8)会导致标签的局部翻转,虽然有效减少了错误连接,但对分割结果质量有不利的影响。在当分割过程中,如果验证集Dice较稳定或逐渐上升则逐步加大权重λ,如果出现验证集Dice下降,需要从新将λ设定为较小的值,并减小λ增加的步长。在得到邻接矩阵Α后,也可以将其应用在未标注的图像上从而实现半监督的训练。如图5所示,在进行半监督训练时,对有标签和无标签的训练数据采用不同的Loss函数。当训练图像具有标签时可以同时使用Segmentation Loss(Dice + Cross-entropy loss)和Non-Adjacency Loss相结合的方式,对于没有标签的训练数据只使用Non-Adjacency Loss。此时,对于无标签数据,NonAdjLoss仍可以通过解剖学先验知识提升标签在小区域内的一致度,减少标签孤立破碎的情况。

图4. 不同脑区之间的相邻关系矩阵

图5. 半监督训练方案示意图
下面的两个表中给出了NonAdjLoss方法的结果,其中Baseline表示未使用NonAdjLoss进行训练的模型(Dice and cross-entropy losses);NonAdjLoss(n)表示使用NonAdjLoss训练的模型,并使用了n例未标注的数据。


可以看到在三个数据集中(MICCAI12,IB-SRv2,Anatomy3), Hausdorff Distance均有明显的改善。而两个非临接数量的衡量指标

和

也有明显的下降。在图6中可以看到baseline中很多错误分割被成功抑制。

图6 左:ground truth;中:只使用经典loss的分割标签;右:使用NonAdjLoss和半监督训练
3. 对两篇论文的总结随着深度学习技术在各个领域的应用逐步深入,人们已从最初的热捧逐步转到冷静的思考。人们发现,目前的深度神经网络在学习能力方面并不那么“智能”,需要大量含有标签的数据来“喂”网络,而且训练数据要尽量涵盖各种实际应用中各种可能出现的情况。简言之,现阶段的神经网络不太会从少量的训练数据中学到内在的规则,难以应付实际应用中纷繁复杂的情况。既然神经网络自己不会总结规则,那么就让人类来教它吧。关于如何把人类的知识传授给神经网络,这两篇文章采用了不同的策略。
第一篇文章采用的是纠错策略,先让神经网络自己从一些包含少量错误标签但是容易得到(自动图谱配准)的大量训练数据中学习一轮,然后通过transfer learning的办法把人类的正确标签用于第二轮纠错训练。这篇文章巧妙地利用了纠错训练只需要少量标签数据的优点,成功减少了人类标记的工作量。值得注意的是,人类标签中的脑区数量是多于自动标签中的脑区数量的,为何要这样?作者在原文中并没有展开讨论,笔者臆测手工标记脑区的数量至少不能少于自动标记脑区的数量,否则将无法对没有手工标记的脑区进行纠错。这种臆测是否合理,应该通过后续的实验来验证。另外,本文的一个亮眼是第二阶段的多任务学习,作者在讨论部分解释为“In general, multi-task learning helps the model to improve the generalization and in our case, to learn features shared by partial segmentation and full segmentation, which can possibly make our encoder more robust. Such claim would need more experiments to prove in the future”。多任务学习可以增强网络对于复杂情况的泛化性,就像一个人面对的任务越多,他考虑问题也会越周全。
第二篇文章采用的策略是直接将domain knowledge设计成loss function用于网络的训练。这个创新点为我们开启了一扇用先验规则来减少人工标记的新方法之门,让我们认识到原来仅凭某种先验规则就可以设计Loss函数并用于无标签数据的训练。笔者惊叹于训练数据中的一大部分并没有标签,针对这部分无标签数据竟然仅凭一个基于规则的loss function就能训练其产生正确分割结果(当然必须还有一部分有标签的训练数据存在)。这扇门一旦开启,今后基于各种先验规则的类似方法可以层出不穷,貌似医学图像分割的标签困难有望极大缓解,干体力活的童鞋们是不是可以喘口气了?数据标记公司们怎么想?以上就是本次与大家分享的两篇关于小数据量弱监督深度学习图像分割的文章,笔者水平有限,文中不当之处还望指正,再会!
参考文献
[1] C. Dai, Y. Mo, E. Angelini, Y. Guo, and W. Bai, “Transfer Learning from Partial Annotations for Whole Brain Segmentation,” 2019.
[2] P. Ganaye, M. Sdika, B. Triggs, and H. Benoit-cattin, “Removing segmentation inconsistencies with semi-supervised non-adjacency constraint,” Med. Image Anal., vol. 58, p. 101551, 2019.
医学图像计算青年研讨会(Medical Imaging Computing Seminar,MICS)创立于2014年,其宗旨是为医学图像领域的华人青年学者提供学术交流平台,增进相互之间的了解和友谊,帮助青年学者融入学术研究大家庭。MICS聚焦于近两年内的医学图像计算领域原创研究,欢迎医学图像处理、计算机视觉、人工智能等新理论、新方法、新应用的展示,以及影像与临床医学、基础医学深度交叉的突破性进展报告。首届MICS在医学图像领域著名学者、北卡罗来纳大学教堂山分校沈定刚教授的倡议下,于2014年12月在深圳大学举行。经过2015(济南)、2016(广州)、2017(上海)、2018(南京)、2019(苏州)的蓬勃发展,MICS从参会人数不足百人到吸引上千名专家学者参与,已迅速成为全国医学图像计算领域最具影响力的活动之一。2020年的MICS会议将于7月18~19日在大连举办,欢迎全球同道专家和同学共聚学术盛宴!

“医学图像计算青年研讨会”微信公众号